
18/11/2022
Por Carlos Nascimento
Sendo um dos primeiros serviços oferecidos pela AWS o Amazon
Simple Storage Service (S3) é um serviço de armazenamento de objetos que possui
alta escalabilidade, durabilidade, disponibilidade e baixa latência.
Para facilitar um pouco o uso de novos usuários preparamos esse artigo para explicar algumas das diferenças entre as classes de armazenamento do serviço:
Amazon S3 Standard
Essa é a classe de armazenamento padrão do S3, ou seja, ao
colocar um objeto dentro de um bucket sem realizar nenhuma alteração essa vai
ser a classe escolhida:
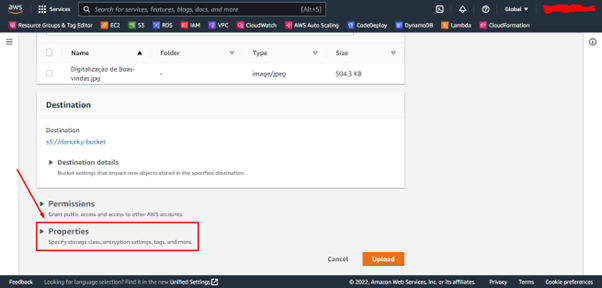
Podemos ver que o S3 Standard é selecionado automaticamente
e as outras classes estão logo abaixo:
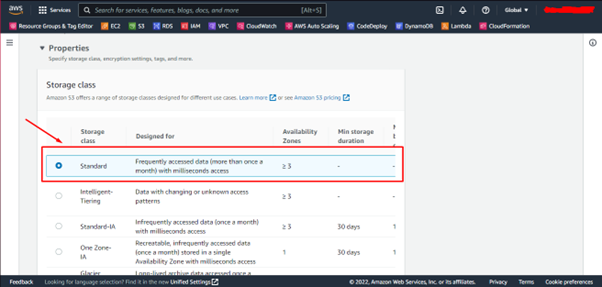
Ela é uma ótima opção para o uso geral, possuindo alta
disponibilidade e performance para dados que serão acessados com frequência,
além de ser muito utilizado para armazenar sites estáticos também, trazendo uma
grande economia se compararmos o
armazenamento de um site por meio de uma instância Amazon EC2 por exemplo.
Amazon S3 Intelligent-Tiering
Essa classe de armazenamento é
utilizada para reduzir os custos de objetos pouco acessados, os movendo para
uma classe mais econômica, possuindo uma projeção de disponibilidade de 99,9%,
sendo um nove a menos do que o S3 Standard que possui 99,99% de projeção de
disponibilidade.
Essa classe de armazenamento atua analisando o padrão de acesso dos objetos e armazena cada um com base nessas análises, e então aponta um nível diferente conforme o uso do objeto, dessa forma se você estiver realizando um backup de dados importantes, mas que você não tem certeza periodicidade do acesso deles, essa classe pode ajudar com o nivelamento dos seus dados. É importante levar em conta se você pretende ter mais controle sobre qual classe de armazenamento você irá utilizar por questões de rápida recuperação de dados, por exemplo.
Amazon S3 Standard-Infrequent Access (S3 Standard-IA)
O S3 Standard-IA é utilizado
para dados que serão pouco acessados mas que mesmo assim precisam ter uma
recuperação rápida quando for solicitado.
É uma categoria muito utilizada para backups, arquivos que ficarão armazenados por um bom tempo ou para arquivos de recuperação de desastres. É interessante mencionar que podemos utilizar uma política de lifecycle para mover um arquivo de uma classe como o S3 Standard para um Infrequent Access, por exemplo.
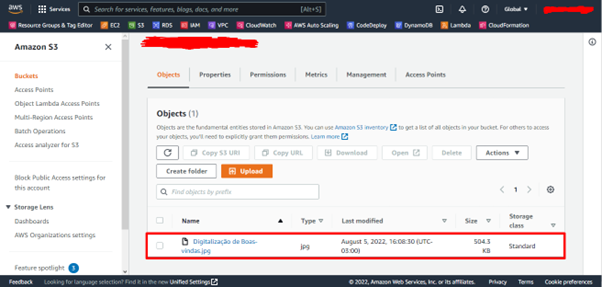
Aqui foi feito o armazenamento
de um arquivo na classe S3 Standard dentro de uma bucket:
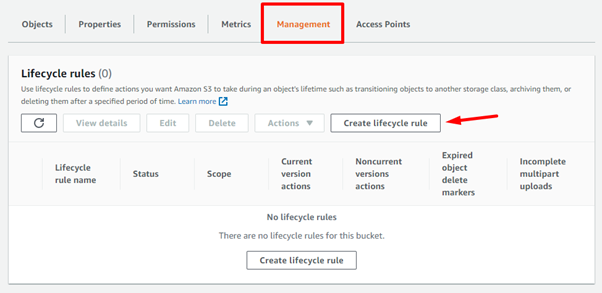
Ao selecionar a aba Managment
nós poderemos configurar uma regra de lifecycle:
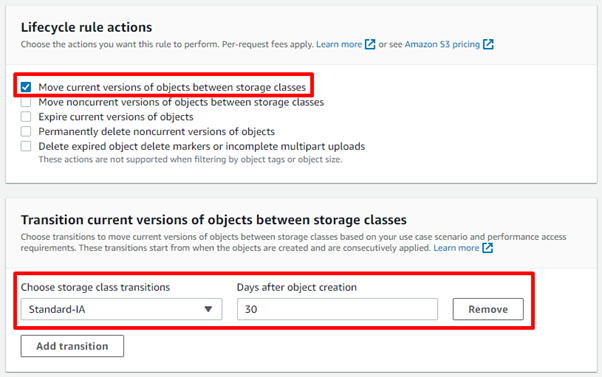
Após configurar o nome de regra
nós podemos encontrar a opção de mover um objeto entre classes de
armazenamento, seguido por outras opções para regras de lifecycle mas para essa
demonstração vamos selecionar a primeira opção, após isso nós devemos
selecionar para qual classe o objeto será movido e depois de quantos dias de
criação isso irá acontecer:
S3 One Zone-Infrequent Access (S3 One Zone-IA)
O One Zone-IA é semelhante ao
Infrequent Access comum, porém ele é armazenado em apenas uma zona de
disponibilidade diferentemente das demais classes do S3 que armazenam os seus
dados em no mínimo três zonas de disponibilidade diferentes, com um custo 20%
mais barato do que o Infrequent Access.
Essa classe é pensada para aqueles que pretendem armazenar dados que não serão acessados com tanta frequência por um valor mais baixo.
S3 Glacier
Chegamos ao S3 Glacier e seus
níveis, essa classe de armazenamento é pensada para aqueles que pretendem
armazenar seus dados por um longo período de tempo e com acesso raro e com um
custo significativamente menor. O Glacier é dividido dessa forma:
S3 Glacier Instant Retrieval
O Instant Retrieval é uma classe
de armazenamento pensada para um acesso de 1 ou 2 vezes por ano, podendo ser
até 68% mais econômico que o S3 Standard-Infrequent Access.
Ele é utilizado para dados que precisam ser armazenados por um longo período de tempo, mas que possam ser acessados imediatamente quando solicitados. Assim como outras classes de armazenamento é possível enviar dados para essa classe por meio do lifecycle.
S3 Glacier Flexible Retrieval
O Flexible Retrieval era
conhecido anteriormente apenas como S3 Glacier, porém com a adição de novas
classes do Glacier foi renomeado para representar melhor sua função.
Ele é um armazenamento durável assim como as outras classes de armazenamento, porém sua recuperação não é instantânea assim como outras classes, podendo demorar horas para recuperar dados armazenados, é uma ótima opção para dados que ficarão armazenados por anos sem serem utilizados, e é uma classe 10% mais econômica do que o Instant Retrieval.
S3 Glacier Deep Archive
O Deep Archive é a classe de
armazenamento mais econômica dos níveis do Glacier, sendo pensado para
armazenamento de 7 a 10 anos ou até mais.
Seu armazenamento é feito por meio de fitas magnéticas por isso o seu custo acaba sendo bem reduzido, porém também são previstos períodos de recuperação, podendo levar de horas ou dia dependendo do tamanho dos dados.
Conclusão
Essas são algumas das diferenças
entre as diversas classes de armazenamento do S3 além de algumas
funcionalidades que podem ajudá-lo a utilizar melhor o serviço, caso queira
saber mais detalhes e casos de uso sobre o serviço é recomendado acessar a
documentação oficial da AWS sobre o assunto.

Equipe de novos talentos do mundo da TI que estão sendo preparados para os desafios da profissão.




