
O pai ta on!!
Em nosso último post falamos sobre o novo pilar do WA: Sustentabilidade, passando pelos princípios do pilar, e o porquê ele foi criado. Agora vamos focar em 3 (três) das 6 (seis) questões que existem no pilar, e quais as boas práticas para cada uma.

Documentação
Primeiramente, preciso compartilhar que a AWS tem um ótimo site onde armazena a explicação detalhada de todos os pilares, e descreve o significado de cada questão e subitem, cito-o:
Dito isso, vamos agora passar pelas 3 primeiras questões do pilar:
Questão 01: Como você escolhe as regiões para apoiar suas metas de sustentabilidade
Essa questão possui apenas um subitem (é a questão mais curta de todo o framework) e o objetivo é justamente avaliar se a escolha da região para hospedar o workload tem como base a sustentabilidade.
Como garantir:
A escolha pode ser baseada nas próprias informações da AWS, note que a região de São Paulo, por exemplo (sa-east-1) não possui projeto de energia renovável próximo, o que a desqualificaria como região sustentável.
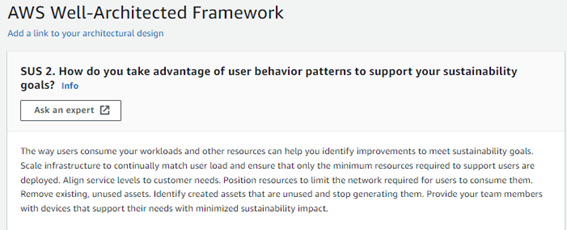
Questão 02: Como você aproveita os padrões de comportamento do usuário para apoiar as metas de sustentabilidade?
A validação nessa questão é a forma com que seu workload consegue se adaptar ao consumo pelos usuários, e como os recursos são posicionados (logica e geograficamente) para atendê-los. Isso ocorre, pois é totalmente possível colocar o workload em Norte Virginia sob o ponto de vista de custos, contudo do ponto de vista de sustentabilidade, a quantidade de energia que o cliente na Tanzânia vai gastar para consumir o dado vai causar impacto.
Como garantir:
Escale a infra com a necessidade do usuário:
1. Escale a infra com a necessidade do usuário: Utilizar serviços serverless, ou mesmo o combo de elasticidade (cloudwatch metrics + elb + asg) é uma ótima forma de garantir.
2. Alinhe os SLAs com as metas de sustentabilidade: Criar as métricas de sustentabilidade são o ponto inicial, com elas é possível avaliar as emissões pelo CUR, e fazer a análise se as metas estão atendendo os requisitos de sustentabilidade criados. Esse item também, provoca o cliente a garantir o último princípio do pilar, ou seja, cobrar terceiros quando ao lifecycle dos dados e ativos. Assim solicitar e/ou ter processos que validem isso é uma forma de atender o item.
3. Pare de utilizar/criar recursos não utilizados: Analisar as métricas de recursos em idle, ou mesmo recursos que podem ser compartilhados (ao invés de ter 12 ALBs, junte em grupos, e segmente via route-path nas rules). É aconselhável também a não processar dados de forma redundante, como armazenar logs no cloudwatch log e em um syslog, ou mesmo ter snapshots manuais e uma política de backup ativa.
4. Otimize a localização geográfica do workload: Resposta mais rápida para isso: CDN. Contudo serviços como ElastiCache, Route53 + geolocalização ou latência também são alternativas interessantes. Obs: No que se tratando de Brasil, talvez esse ponto acabe conflitando com a questão01 do pilar.
5. Otimize os recursos para a equipe: Esse é um item bem interessante, onde basicamente é coberto por utilização de desktops virtuais como o workspaces ou até mesmo o appstream (existe um ótimo artigo comparando os dois aqui no blog). Contudo possuir aluguéis de máquinas físicas também pode ser um ponto a ser considerado, desde que se cobre do fornecedor o mesmo zelo e metas de sustentabilidade.

Questão 03: como você aproveita os padrões de arquitetura para apoiar suas metas de sustentabilidade?
Ao passo que a questão 02 cobra dos padrões de comportamento, a questão03 cobra dos padrões de arquitetura, e sim, nesse ponto é onde temos cross-overs entre os pilares de performance, confiabilidade e custos. A questão no que tange a sustentabilidade, analisa como funcionam a análise de performance e componentes ociosos, assim como a retro compatibilidade dos dispositivos para consumir o seu workload.
Como garantir:
Escale a infra com a necessidade do usuário:
1. Otimize o software e a arquitetura para trabalhos assíncronos: Utilizar microsserviços que vão desde segmentá-los no ECS (note que não é só criar containers, e sim segmentar o serviço) até o EKS é uma forma de garantir, contudo é possível também descomissionar as solicitações em filas com o SQS + Lambdas, até mesmo o combo ELB + ASG + Cloudwatch metrics. Outro ponto bem interessante nesse item é pensar no timestamp do workload, e segmentá-lo ao ponto de ter um processamento constante ao invés de picos.
2. Remova ou refatore recursos com uso baixo: Mais uma vez temos pontos que provocam a utilização da escalabilidade da nuvem. O ponto adicional nesse item é que ele prova também a análise constante da utilização completa dos recursos, e isso pode ser atendido com um processo de ferramentas como o compute optimizer, o trust advisor, e até mesmo o cost explorer. Note que para todos esses itens é possível criar métricas no cloudwatch, com alarmes via SNS.
3. Otimize códigos que consomem mais tempo ou recursos: Manter a monitoração com o cloudwatch é um bom início, contudo o item cobra inclusive análise de código backend, que pode ser garantido com ferramentas como o CodeGuru ou o SonarCube. Além disso é cobrado que se mantenha atualizado as versões das linguagens utilizadas tanto nos lambdas quando no backend da aplicação.
4. Otimize o impacto sobre dispositivos do cliente: um dos pontos mais interessantes do pilar, aqui a recomendação é que você garanta a retro compatibilidade da aplicação com dispositivos antigos, isso pode ser feito desde utilizar o device farm da AWS, até mesmo utilizar otimizar as atividades mais pesadas da aplicação no servidor ao invés do equipamento dos usuários, o que de certa forma poderia ser garantido com o appstream 2.0.
5. Use arquiteturas que comportem de melhor os padrões de armazenamento e acesso a dados: Inicialmente analisar os comportamentos de acesso e utilização de dados com ferramentas como o performance insights vai ajudar a entender o padrão de utilização, contudo o principal ponto nesse item é como gerenciar o lifecycle do dado em si, o que vai desde utilizar arquivos em formatos mais eficientes como o Parquet a até mesmo utilizar datalakes para otimização de acesso.
That’s all folks! Be Happy!!!

Thiago Marques
Technical Account Manager
thiago.marques@darede.com.br
Technical Account Manager da Darede, formato em Rede de Computadores, e pós graduado em Segurança da Informação. Possui ampla experiência em Datacenters e Service Providers, além de ser um entusiasta em DevOps e mercado financeiro.





