
Autor: Éverton Trindade
Data 29/01/2025
Olá, pessoal!
Hoje resolvi abordar um tema pouco falado, depois de ter me deparado com uma situação inusitada sobre o assunto.
Muitos ambientes utilizam o Zabbix como ferramenta de monitoramento de atividade e desempenho, especialmente para bancos de dados. No entanto, nem sempre estamos familiarizados com as flags ou métricas coletadas por essa ferramenta.
A flag do Zabbix que abordarei aqui é o “Worktables from cache ratio”. Sim, há quem utilize essa métrica como um “medidor de desempenho” de um banco de dados. Meu objetivo aqui é garantir que, ao receber um alerta desse tipo, você entenda que a situação já estava crítica há algum tempo. Ou que, pelo menos, uma cortina de fumaça já vinha se alastrando.
Mas, para compreender melhor a situação, precisamos primeiro entender o que são esses Worktables e para que servem. Para isso, investi um bom tempo (mais de 30 horas) realizando testes, coletas e pesquisas.
E, para enriquecer ainda mais a discussão, convido você a compartilhar experiências sobre o assunto, caso já tenha se deparado com alertas desse tipo.
Quando e onde os Worktables são construídos?
Na maioria das vezes, o SQL Server executa operações lógicas para processar consultas e, para isso, constrói os Worktables no TempDB. Esses objetos temporários (não confundir com #tempTables) estão associados ao uso de cursores e a consultas que envolvem cláusulas como DISTINCT, CROSS JOIN, ORDER BY, GROUP BY, entre outras. Todas essas operações são executadas a nível de TempDB.
Para desmistificar ainda mais o assunto, os Worktables também são chamados de Table Spool. O otimizador de consulta os implementa como tabelas ocultas no TempDB. Ele utiliza esses objetos quando julga necessário armazenar temporariamente os dados para posterior reutilização, evitando acessos repetitivos a uma mesma tabela e reduzindo a necessidade de buscas ou varreduras (seeks and scans).
Ainda tem dúvidas? Confira a consulta abaixo e seu respectivo plano de execução:
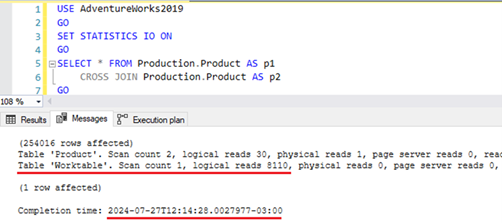
Criação da tabela Worktable pelo otimizador
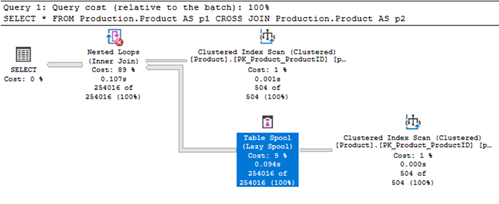
Table Spool relacionado ao Worktable
E assim confirmamos que as Worktables são um processo interno realizado pela própria engine, já que a tabela em si não existe fisicamente no banco de dados:
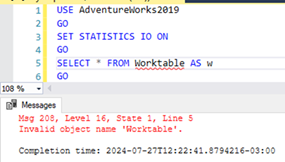
A tabela realmente
não existe
E por que dos sinais de fumaça?
Por três motivos:
- O uso intenso e significativo dessas atividades pode indicar uma possível contenção a nível de disco.
- O TempDB pode estar mal configurado, mal distribuído ou apresentar problemas no disco onde os datafiles estão localizados (baixo desempenho ou partição inadequada).
- Pouca memória disponível no servidor.
Não irei estender este artigo abordando todos os motivos especificados acima, mas abordarei ao menos o item de número três (3): Insufficient memory.
Mas calma, isso não significa que o item escolhido seja o mais importante, nada disso. Muito pelo contrário, os demais itens precisam ser levados em consideração em análise de performance também.
Acontece que podemos nos deparar com situações em que uma pressão de memória no servidor pode ser ignorada enquanto “aguardamos” por alertas relacionado ao “Worktables from cache ratio”.
O fato das Worktables serem armazenadas em cache é o que faz com que a próxima execução de uma mesma consulta seja mais rápida. Mas quando um servidor tem pouca memória, um plano de execução pode ser removido do cache e todas as Worktables associadas também são descartadas.
E para demonstrar esse tipo de situação fiz questão de criar, propositadamente, uma tabela com mais de 3 milhões de registros sem índice algum (isso mesmo, nem mesmo PK) em meu ambiente de teste. E para piorar ainda mais a situação, configurei para que o SQL Server utilize apenas 1GB de memória do meu desktop.
Resultado: A tabela que criei não pode ser alocada por completo na memória. E o que isso significa? Haverá muitas trocas de páginas (consulta em disco). Criação do banco e da tabela, ambos denominado Worktables:
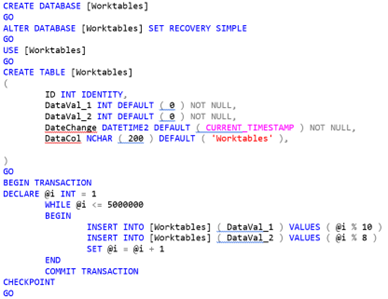
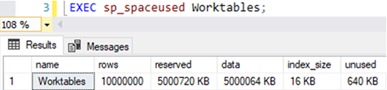
Detalhes da tabela
criada recentemente
Para ser justo, aproveitamos para limpar todo o cache do servidor:
Não faça isso em
ambiente de produção!
Para tornar a análise ainda mais precisa, configurei um coletor no S.O. para registrar e acompanhar o comportamento das métricas especificadas. Vejam só:
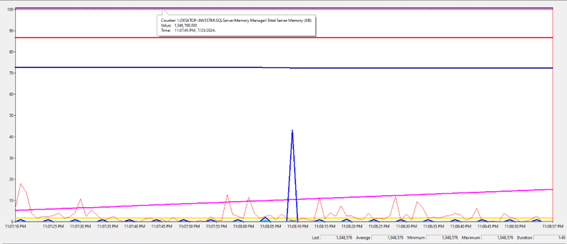
SQL Server
configurado para utilizar apenas 1GB de RAM
Memória livre
disponível
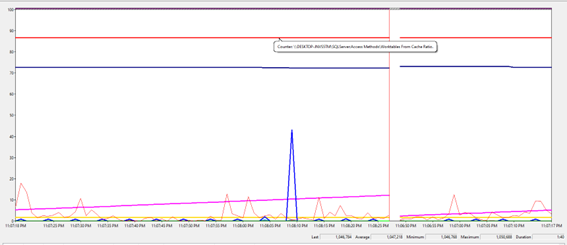
Métrica relacionado
ao Worktable From Cache Ratio
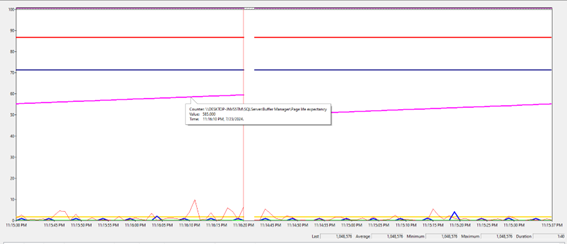
Métrica relacionado
ao PLE (Page Life Expected)
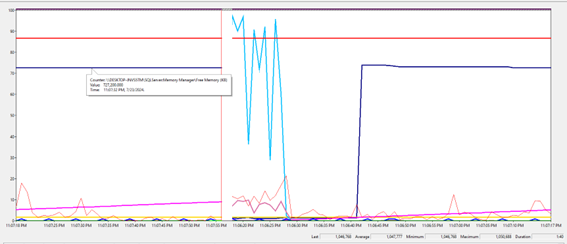
Agora observe o comportamento do gráfico assim que realizamos uma consulta completa na tabela Worktables (full scan):
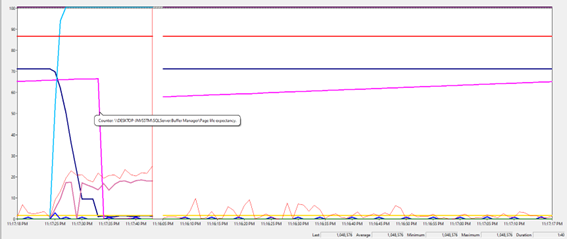
Percebemos uma queda
abrupta do PLE e alocação de toda memória livre pelo SQL Server
No decorrer do processo, percebemos que a métrica relacionada ao Worktables From Cache Ratio permanece intacta enquanto a casa está pegando fogo. Prova disso é que as linhas que representam a disponibilidade de memória e o tempo de vida das páginas mal aparecem no gráfico abaixo:
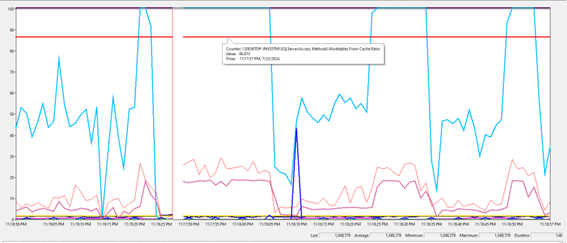
Métrica relacionado
ao Worktable From Cache Ratio
O que podemos concluir?
Focar apenas em alertas relacionados ao Worktables e ignorar outras métricas que indicam pressão de memória ou problemas de performance pode levar a decisões equivocadas. Quando se trata de desempenho, é essencial realizar uma análise minuciosa e considerar diferentes contadores.
Por hoje é só, pessoal!
Até a próxima! ?

Éverton Trindade
Administrador de Banco de Dados
Éverton Trindade é Administrador de Banco de Dados Jr na Darede, com especialização em DBA SQL Server e PostgreSQL. Detém certificações Microsoft em Azure Fundamentals, Azure Data Fundamentals, Azure Database Administrator Associate e Azure AI Fundamentals, além de conhecimentos sólidos em Linux System Administration e Linux Network Engineering.





