
O pai ta on!!
Já falamos
sobre os sistemas descentralizados, o comparativo entre os repositórios, e
iniciamos nosso projeto.
Nesse post falaremos
o funcionamento de logs e como entender o status.
Somado a isso
veremos como funcionam os repositórios remotos, e como podemos enviar nossos
trabalhos locais para esses repositórios, e assim obter um dos principais
ganhos do git: o poder de dividir para conquistar.
Inspecionando logs
Chegamos o git
log trabalhando em nosso último post, e aqui vamos nos aprofundar no
assunto.
Em definição o
git log exibe o histórico de commits, e por padrão o comando mostra
informações como autor, timestamp, comentário e o hash do commit,
o que é rico em informação, contudo em um projeto com diversos commits
pode acabar gerando uma confusão gigante.
Abaixo estão
os principais parâmetros para esse comando.
git log
–oneline: o comando que mais gosto, e o motivo para eu sugerir
fortemente um padrão nos comentários, pois acaba ajudando muito na análise.
Veja a diferença de não se ter um padrão no comentário:

E ter o padrão:

Note que no comentário colocamos o título, seguido de um
‘enter’ e só então a explicação detalhada do commit, isso é eficiente
pois com o –online, vemos apenas o título, o que facilita muito na
pesquisa das alterações.
Some essa característica a um sistema de nomenclatura de FIX,
UPDATE, UPGRADE, BUG e etc, de dará um poder gigante de análise.
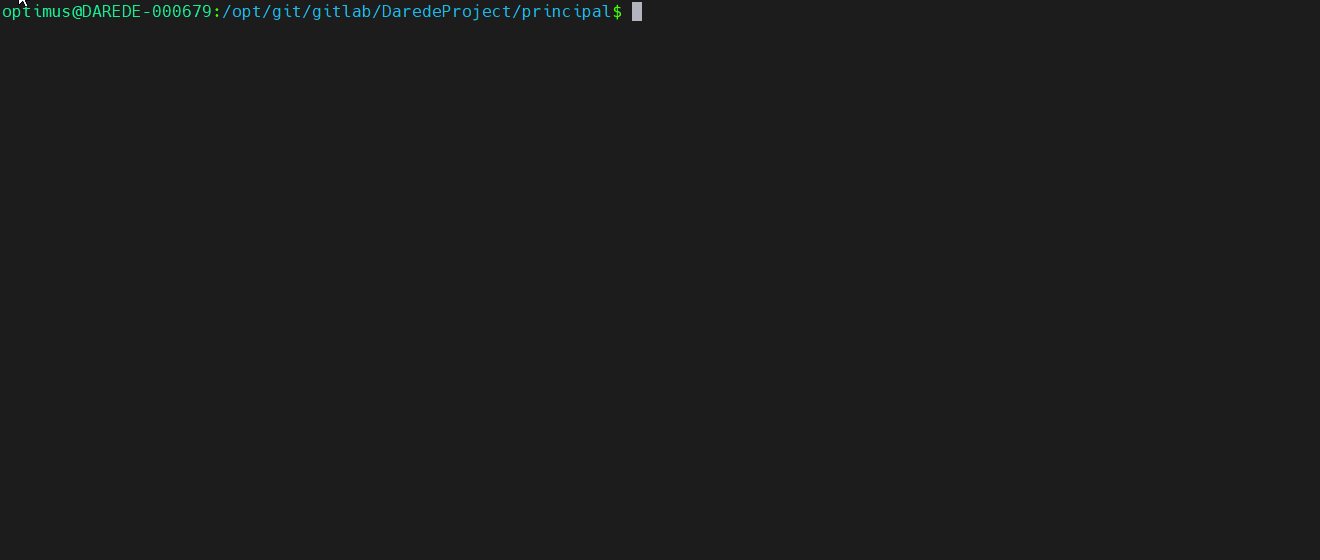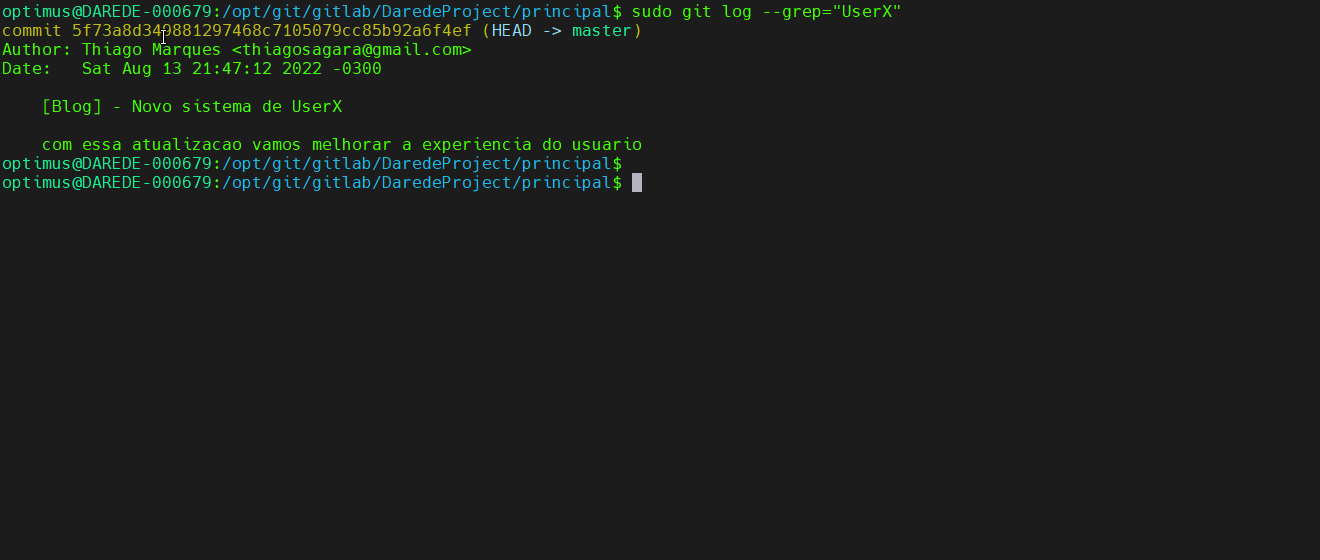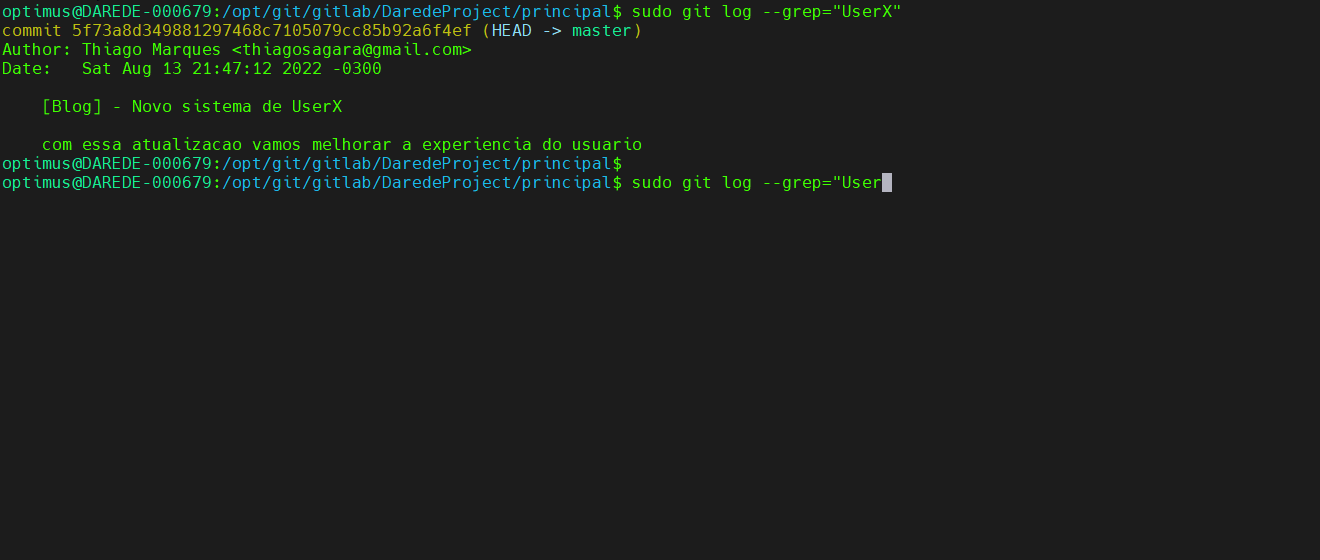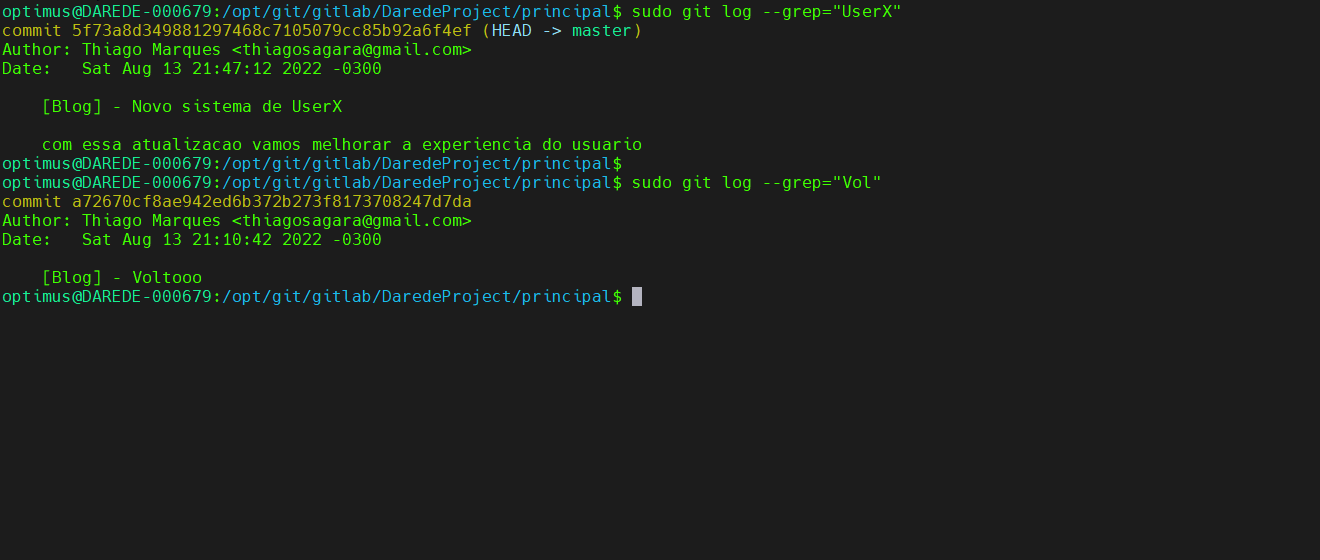
git log –grep=”<padrão>”: faz uma
pesquisa baseado no padrão de string no comentário, e novamente essa função
somada a anterior vai te dar grande poderes.
Finalizando
temos o git log -n <quantidade> que funciona de forma
parecida com o comando tail no Linux, ou seja, vai mostrar os últimos “n”
logs do histórico
Inspecionando o estado
O git
status vai ser seu melhor amigo para identificar quais arquivos estão na
área de staging, e aqui vale uma abertura de parênteses importante: as áreas no
git.
Existem
basicamente 3 areas no Git:
·
Working directory: que é onde se trabalha
de fato na edição de arquivos. Nessa área não existe interação com o
repositório, e não executamos nenhum comando git ainda. Contudo sempre que
houver uma alteração ou uma adição de novos arquivos o working dir vai mostrar
que existem arquivos que estão fora do repositório;
·
Staging área: Aqui já abordamos ligeiramente,
e basicamente é uma área temporária do git, ou seja, ela não está nem no
working dir, nem no repositório. Tem como principal objetivo servir como uma
validação adicional dos arquivos antes de enviar para o repositório.
Adicionamos um arquivo ao staging com o comando git add.
·
Repositório: Por fim temos a última área
que é de fato quando o arquivo esta dentro do repositório, e já possui controle
de versionamento, e adicionamos arquivos nessa área com o comando git commit.
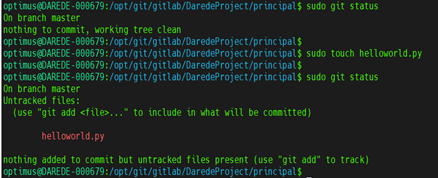
Assim o git
status é a forma de verificar se existe algo na área de working dir e
staging. Isso ajuda muito, pois assim saberemos se existem arquivos que
pendentes de commit, ou até pendentes de add. Note que ele não
mostra histórico (isso é função do git log), apenas o realtime.
Repositórios remotos
Até agora
trabalhamos apenas localmente, ou seja, criamos nossos códigos/arquivos, e
adicionamos eles no git para controle de versionamento. Agora vamos adicionar
mais uma etapa, que é justamente poder enviar nossos dados para o repositório remoto.
Isso pode ser
feito tanto se a estrutura for a publica (onde basicamente se utiliza os sites
de repositório mostrado no segundo post sobre o GIT), ou privada (que também
pode ser os repositórios mostrados, mas é mais comum ser uma estrutura
interna).
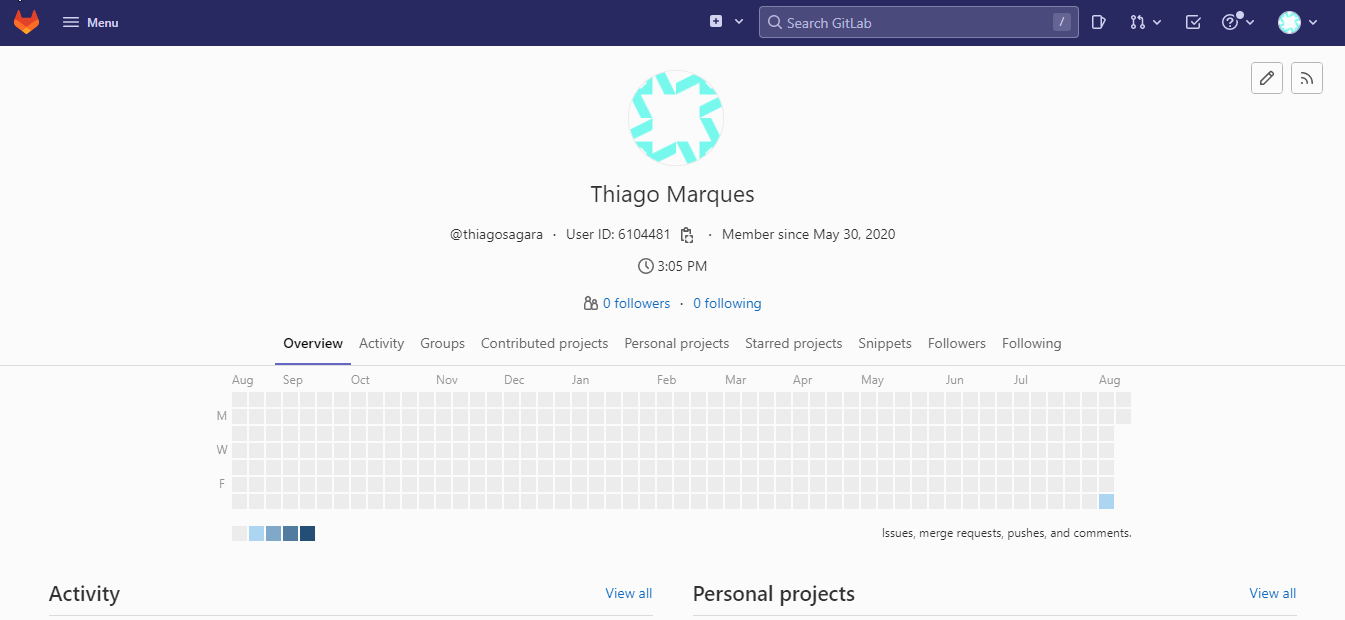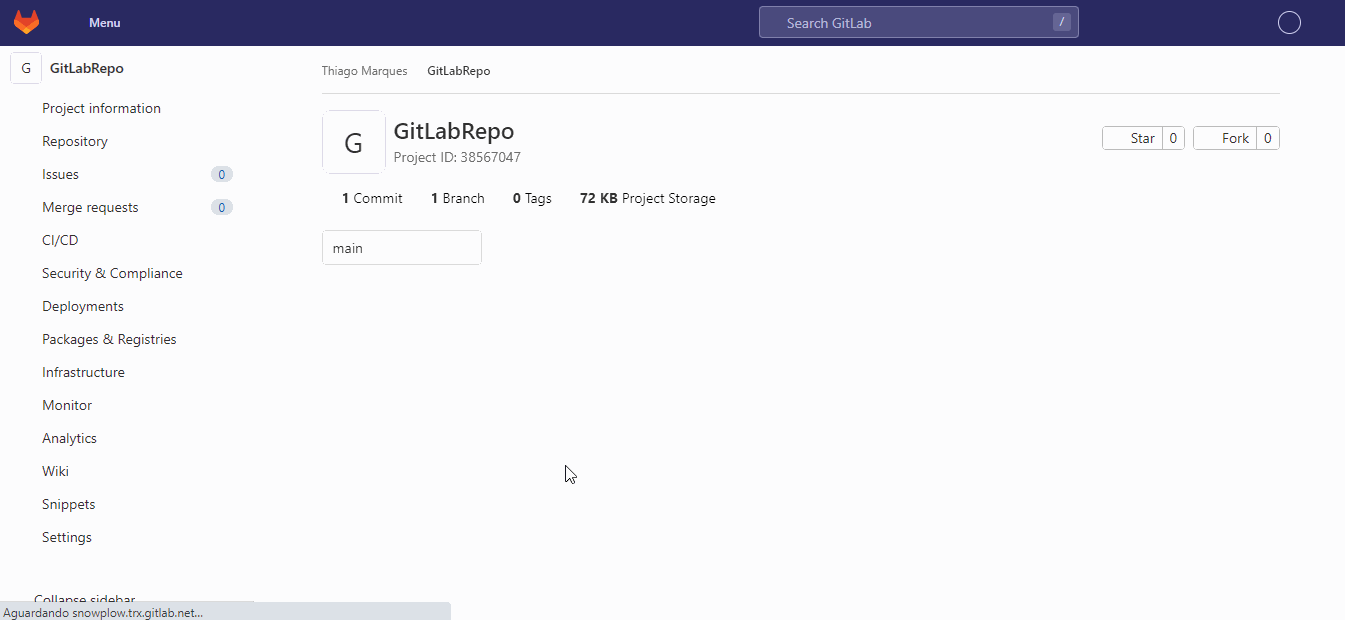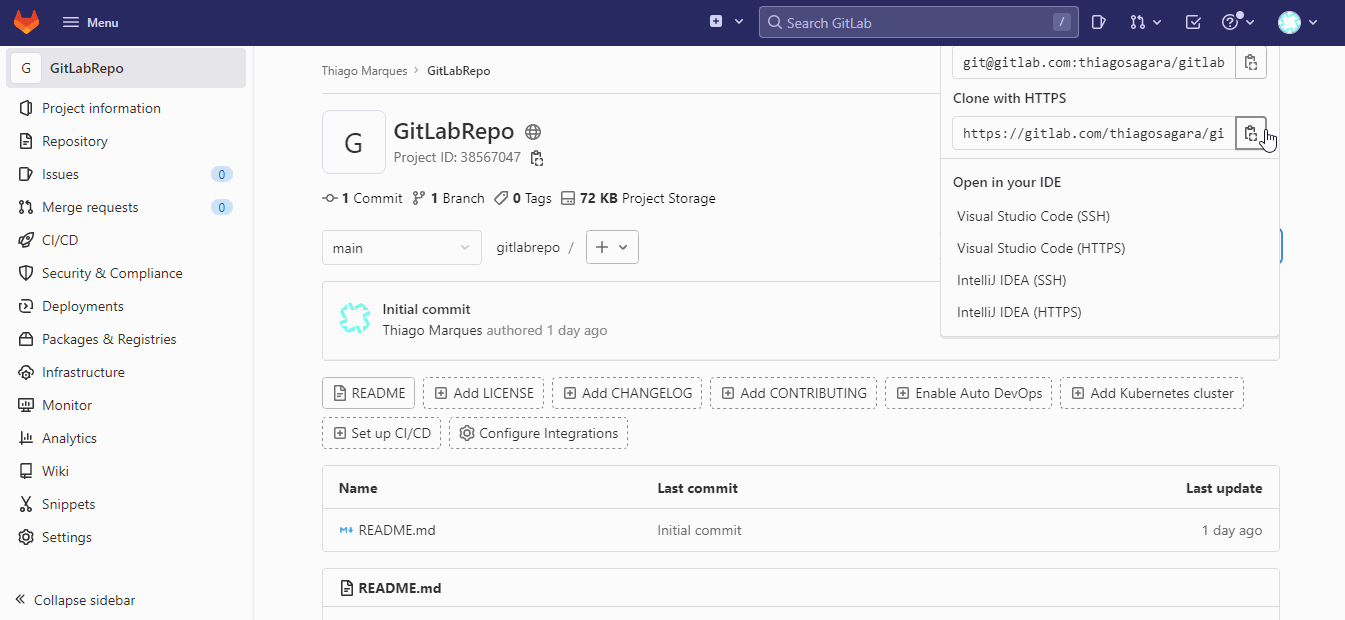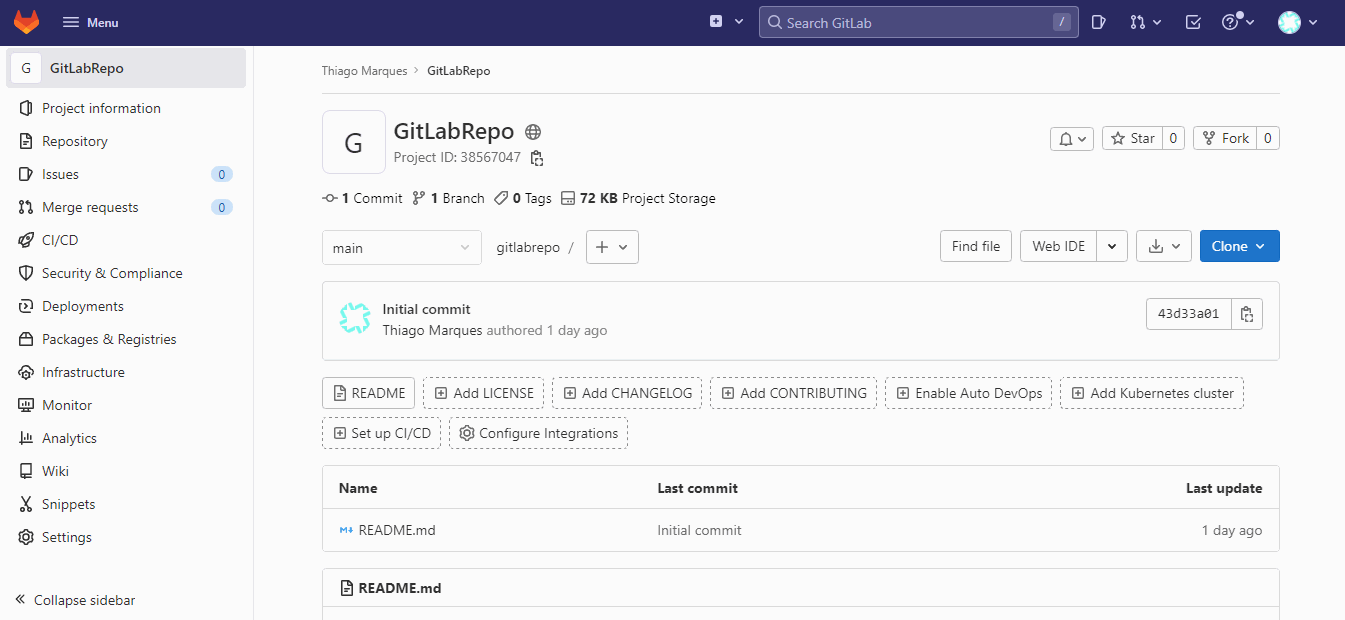
Antes de tudo
vamos adicionar o nosso repositório remoto. Isso é feito com o comando git
remote add, mas antes de executar o comando precisamos copiar a url do
repositório remoto. Para isso vamos no site do repositório, e copiamos a url
(eu prefiro trabalhar com a opção HTTPS):
Copiado o
repositório, agora vamos adicioná-lo em nosso console:
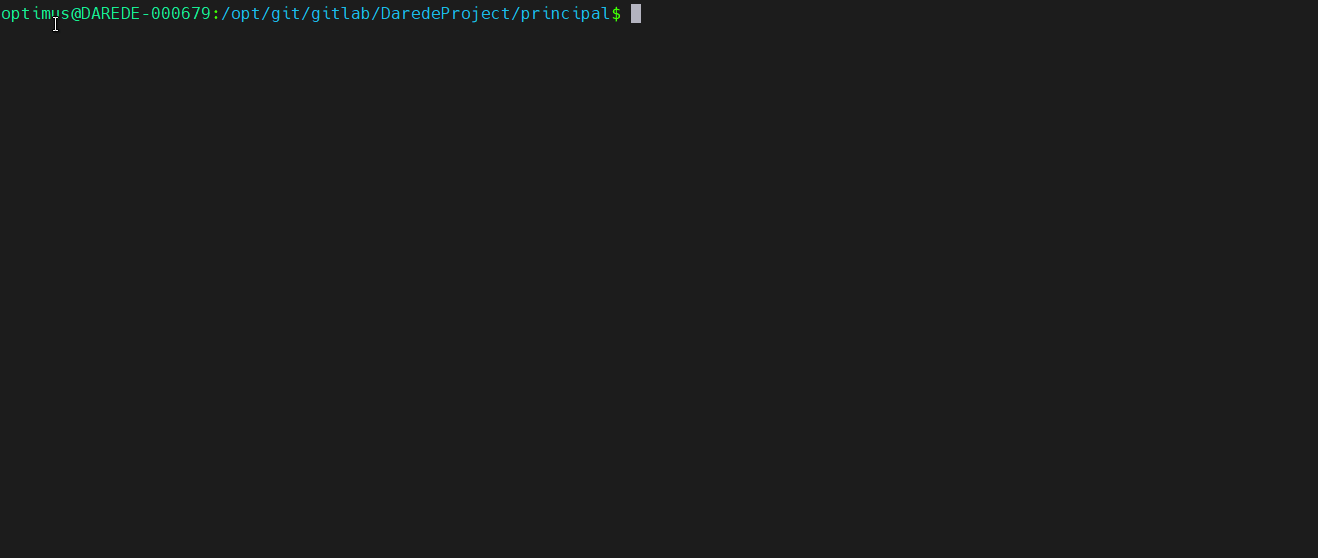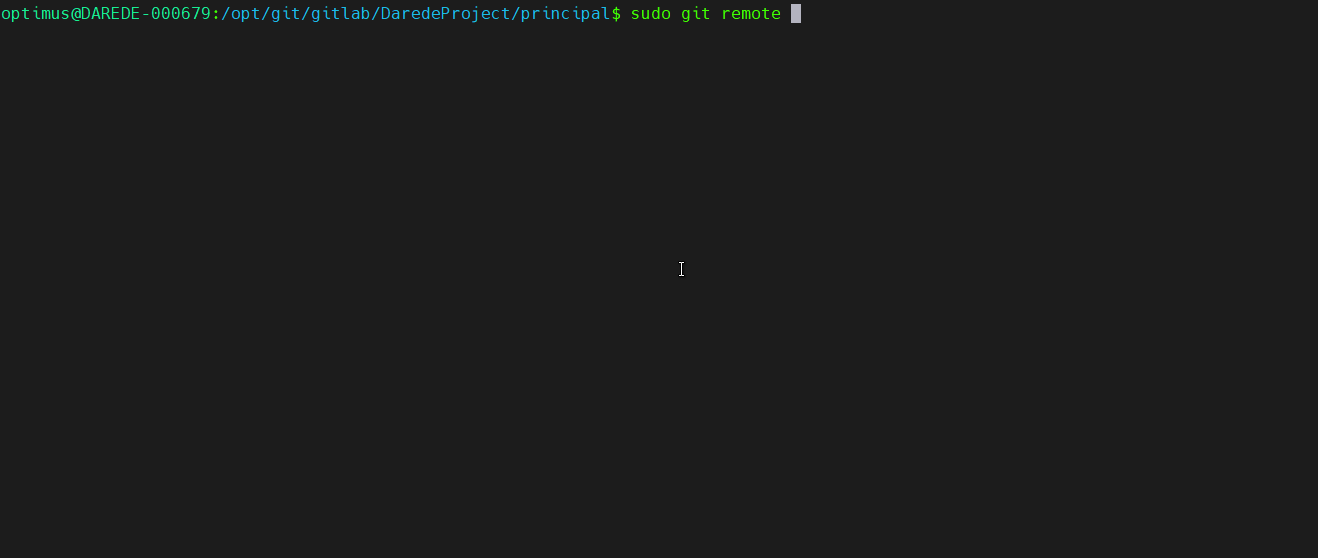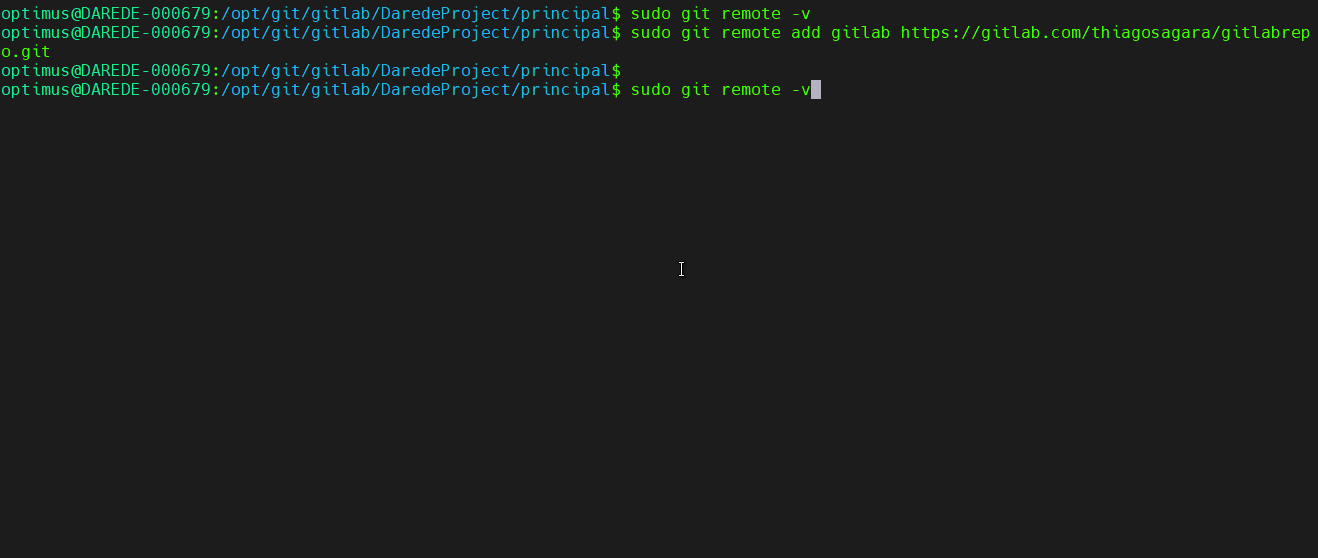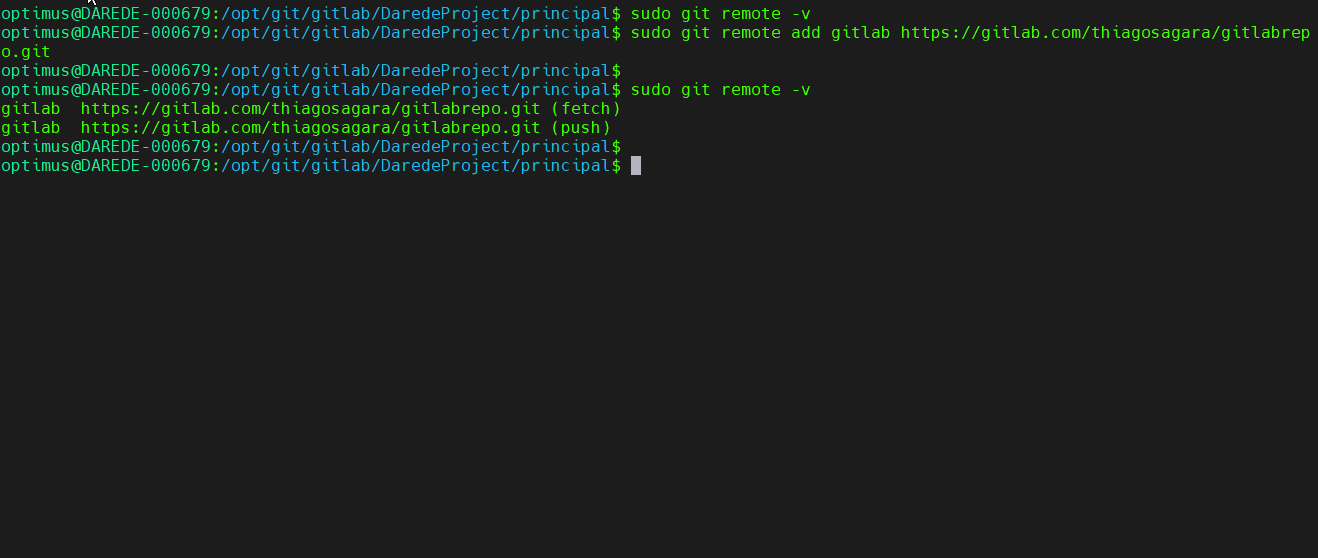
Após isso
podemos verificar o repositório com o comando git remote -v
Enviando o projeto para o repositório remoto
Note que na etapa anterior nomeamos nosso repositório remoto
como ‘gitlab’, e agora vamos enviar todos os arquivos/códigos para esse
repositório, o que é de fato a principal função do comando git push, ou
seja, ele (o push) faz a exportação dos commits que fizemos localmente para o
repositório remoto em uma branches (veremos isso mais para frente) específica.
Isso é feito com o seguinte comando:
#git
push <nome_do_repositorio_remoto> <nome da branch>
git push -uf gitlab main
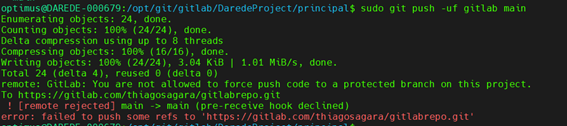
Contudo antes
de enviar nossos arquivos precisamos atualizar no nosso projeto. Isso é
necessário, pois criamos quando criamos o projeto no site por ‘baixo dos
panos’, ele também cria uma estrutura git nos servidores, assim também existe
um histórico de commits feitos.
Como no git,
para o controle de versionamento ser efetivo ele precisa ter um histórico
único, primeiro precisamos atualizar os históricos remotos, e só então enviar
os nossos.
Para isso utilizamos
o comando:
#git
pull <nome_do_repositorio_remoto> <nome_da_branch>
–allow-unrelated-histories
git
pull gitlab main –allow-unrelated-histories

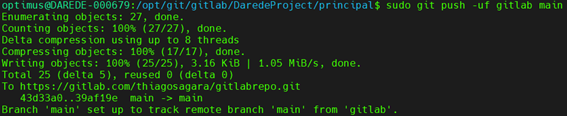
Agora podemos
rodar o git push novamente e teremos nosso projeto atualizado no repositório
remoto:
That’s all
folks! Be Happy!!!

Technical Account Manager da Darede, formado em Rede de Computadores e pós-graduado em Segurança da Informação. Possui ampla experiência em Datacenters e Service Providers, além de ser um entusiasta em DevOps e mercado financeiro.





