
14/09/2023
Por Thiago Marques
O pai ta on!!
Nos últimos anos, o cenário de banco de dados evoluiu consideravelmente, e com ele surgiram diversas opções para atender diversas necessidades de armazenamento e gerenciamento de dados. Muito além de banco de dados relacionais, hoje já possuímos banco de dados gráficos, banco de dados distribuídos, banco de dados de séries temporais e até bando de dados ledger.
Uma dessas linhas de desenvolvimento, foi algo relativamente disruptivo para época (onde os bancos relacionais dominavam), que era um conceito justamente contrário, ou seja: um banco de dados não-relacional, também conhecido como NoSQL.
Neste artigo, vamos explorar o Amazon DynamoDB, que é a solução de NoSQL oferecida pela Amazon Web Services, também conhecida como AWS.
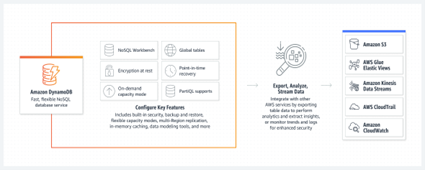
O que é um banco de dados não-relacional
Edgar Frank Codd foi um matemático que decidiu usar sua genialidade para desenvolver o primeiro modelo do que chamamos de bando de dados relacionais, ou seja, onde uma tabela pode ser relacionada a outra usando um atributo, que durante mais de 2 décadas foi o principal modelo de dados utilizados em bancos como Oracle, DB2, MySQL e PostGreSQL.
Contudo, por volta do início dos anos 2000 entra em cena discussões de uma forma mais simples e escalável, e então surgiu a ideia de se utilizar uma estrutura chave-valor, característica principal de um NoSQ, adicionalmente, os bancos de dados não-relacionais permitem uma estrutura mais flexível para armazenar informações. Essa flexibilidade torna-os ideais para lidar com grandes volumes de dados não estruturados ou semiestruturados, comuns em aplicativos modernos, como aplicativos da web, jogos e IoT.
Os bancos de dados não-relacionais podem ser divididos em várias categorias, como bancos de dados de documentos, bancos de dados de chave-valor, bancos de dados de colunas e bancos de dados de grafos. O Amazon DynamoDB se enquadra na categoria de bancos de dados de chave-valor.
Vantagens do DynamoDB
Se tratando do serviço de database NoSQL da AWS, o DynamoDB herda as características clássicas de uma DB não relacional, além de garantir vantagens de ser altamente escalável, e totalmente gerenciado. O DynamoDB foi projetado para garantir um alto desempenho e disponibilidade, permitindo que o foco fica na construção de aplicativos, e não na infraestrutura para suportá-lo.
Outra grande característica do serviço é o Amazon DynamoDB Accelerator (DAX), que é um sub-serviço capaz de gerenciar cache em memória, e assim melhorar o desempenho de consultas de leitura na database.
Outras características do DynamoDB, incluem, mas não se limitam a:
Escalabilidade
Escalabilidade automática permite que você aumente ou diminua a capacidade de armazenamento e leitura/escrita conforme a demanda, sem tempo de inatividade, o que por padrão já é uma vantagem gigante frente a maioria dos bancos de dados relacionais, e mesmo não-relacionais baseados em infra (IaaS).
Latência
Mesmo tendo uma latência de processamento mais baixa que outras bases de dados, com a utilização de cache com o DAX, os resultados das consultas mais frequentes são realizados em memória, o que reduz significativamente a resposta de consultas subsequentes.
Disponibilidade
Além de ser um serviço gerenciado, o deploy de um banco dynamodb é feito em com replicações automáticas de dados em várias zonas de disponibilidade, o que garante a continuidade da aplicação e a resiliência contra falhas.
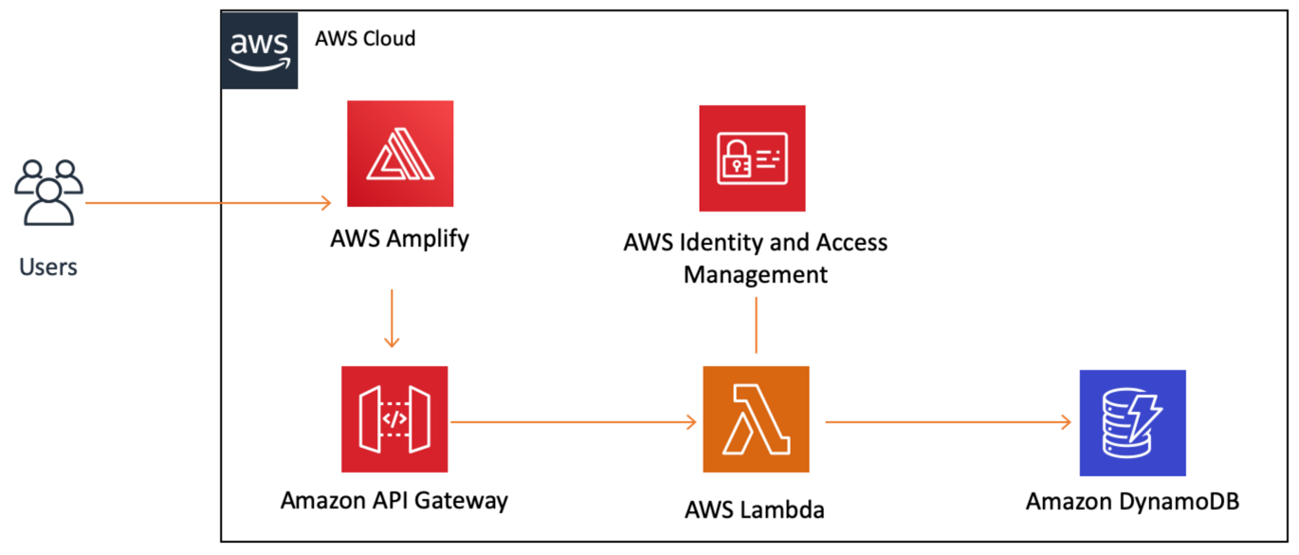
No exemplo abaixo temos exemplo de uma aplicação WEB, 100% serveles, com a utilização do Amplify/API Gateway e Lambda para frontend, e trabalhando com o DynamoDB com base de dados.
Onde usar o DynamoDB
De fato, o um bando NoSQL tende a ser criado em ambientes onde a quantidade de requisições é muita alta, e/ou a latência necessária para acessar o dado é uma medida essencial para a aplicação.
Dessa forma cases onde o DynamoDB pode ser utilizado são:
Aplicativos de Jogos Online: Onde a latência é um fator crítico para a solução (ninguém gosta de delay), garantindo uma experiencia de um jogo fluido.
IoT: Talvez o maior case de sucesso para chave-valor, uma vez que a quantidade de dados, e sobretudo a quantidade de dados gerados ultrapassa os padrões ‘normais’ de um banco.
Gerenciamento de Sessão e Autenticação: Mantendo o estado de sessões de usuários de maneira eficiente, garantindo por exemplo a escala de outras aplicações de maneira mais eficiente.
Infra como Código
Como sempre vamos ver um exemplo de código para criar o deploy em python:
import boto3
dynamodb_client =
boto3.client(“dynamodb”)
dynamodb_client.create_table(
TableName=”dynamodb_table”,
KeySchema=[{“AttributeName”:
“id”, “KeyType”: “HASH”}],
AttributeDefinitions=[{“AttributeName”:
“id”, “AttributeType”: “S”}],
)
rds_client = boto3.client(“rds”)
# Criar um
banco RDS
rds_client.create_db_instance(
DBName=”RDS_database“,
DBInstanceClass=”db.t3.micro”,
Engine=”mysql”,
AllocatedStorage=20,
)
# Criar um
cliente DMS
dms_client =
boto3.client(“dms”)
# Criar um endpoint DynamoDB
dms_client.create_endpoint(
EndpointIdentifier=”dynamodb_endpoint”,
EngineName=”dynamodb”,
ServiceAccessRoleArn=”arn:aws:iam::123456789012:role/my-dms-role”,
)
# Criar os
endpoints para RDS e DynamoDB
dms_client.create_endpoint(
EndpointIdentifier=”rds_endpoint”,
EngineName=”mysql”,
ServiceAccessRoleArn=”arn:aws:iam::123456789012:role/my-dms-role”,
)
# Criar um
canal de replicação
dms_client.create_replication_channel(
ReplicationChannelName=”replication_channel”,
ReplicationInstanceArn=”arn:aws:rds:us-east-1:123456789012:db:RDS_database
“,
ReplicationEndpointArns=[“arn:aws:dms:us-east-1:123456789012:endpoint/dynamodb_endpoint”,
“arn:aws:dms:us-east-1:123456789012:endpoint/rds_endpoint”],
)
# Criar uma
tarefa de replicação
dms_client.create_replication_task(
ReplicationTaskIdentifier=”replication_task”,
ReplicationInstanceArn=”arn:aws:rds:us-east-1:123456789012:db:RDS_database
“,
ReplicationTaskSettings={“CdcStartPosition”:
“START_AT_EARLIEST_AVAILABLE”},
ReplicationTaskSourceIds=[“dynamodb_endpoint”,
“rds_endpoint”],
)
OBS.: AS ARNs
aqui descritas são EXEMPLOS, altere para role utilizada em sua conta
Xero no suvaco!! Be Happy!!!

thiago.marques@darede.com.br
Technical Account Manager da Darede, formato em Rede de Computadores, e pós graduado em Segurança da Informação. Possui ampla experiência em Datacenters e Service Providers, além de ser um entusiasta em DevOps e mercado financeiro.





